本文讲解的eventHook基于Locust的1.x版本。
一、基本介绍
Locust的event.py模块包含了两个类,一个是事件钩子定义类EventHook,一个是事件钩子类型类Events,为不同的事件提供hook。事件处理函数注册相应的hook以后,我们可以很方便的的基于event触发处理函数,实现事件驱动。
EventHook定义了三个方法:
def add_listener(self, handler):
self._handlers.append(handler)
return handler
def remove_listener(self, handler):
self._handlers.remove(handler)
def fire(self, *, reverse=False, **kwargs):
if reverse:
handlers = reversed(self._handlers)
else:
handlers = self._handlers
for handler in handlers:
handler(**kwargs)
可以看到add_listener、remove_listener的作用是注册或删除监听函数,fire方法是触发处理函数。EventHook的实现相比Locust 0.x版本有较大改变(不再使用Python的内置魔方方法)。
Events中包含了11个事件钩子,分别是:
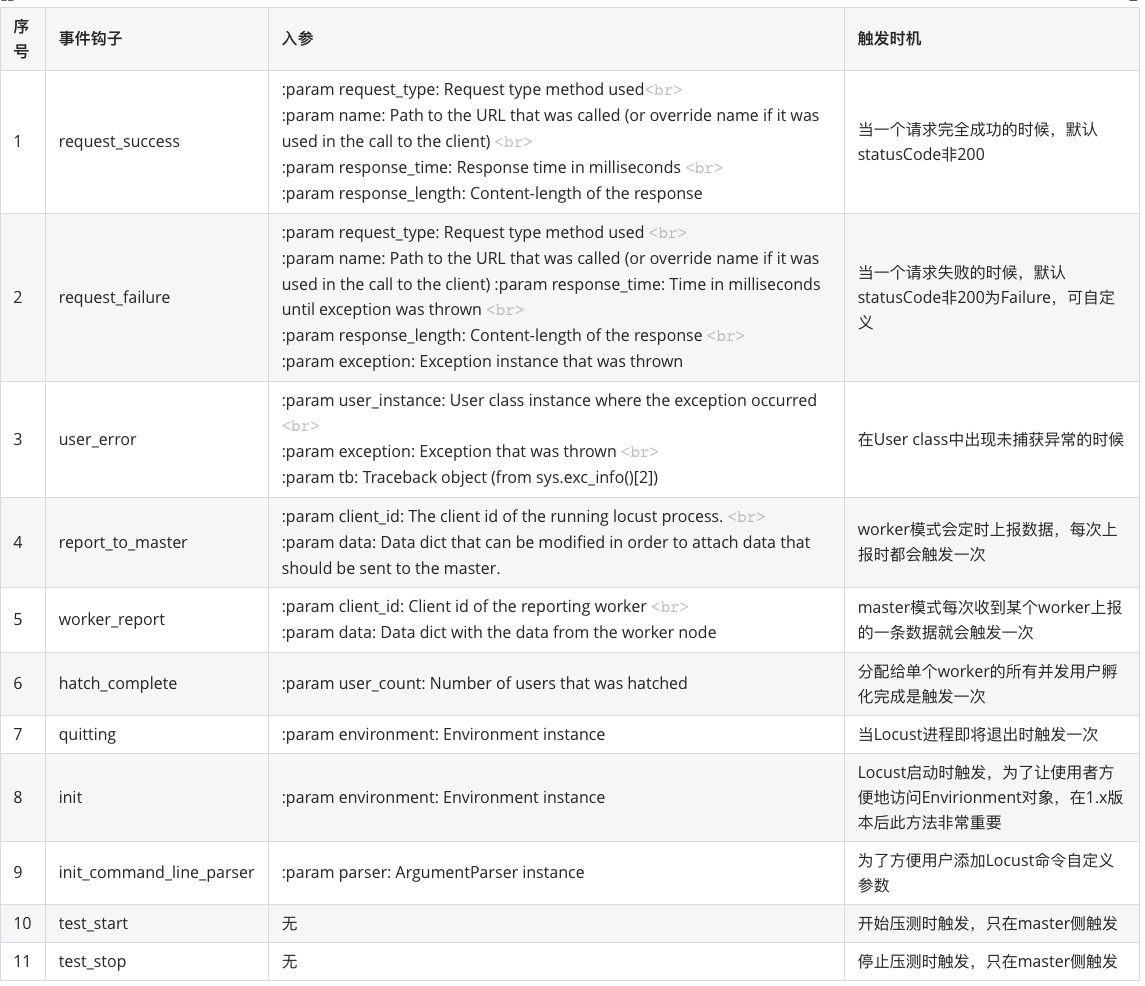
二、事件钩子的实现原理
事件钩子的原理可以简单理解成,1.定义处理函数 ——> 2.注册到某个eventHook ——> 3.在某个时机触发eventHook ——> 4.该eventHook遍历执行所有处理函数。在代码层面就是定义函数,然后add_listener,最后在想要的位置触发eventHook的fire方法并传入定义好的参数,这里参数是固定的,不能随意传入,之所以每个处理函数都能对参数进行修改,是因为这里的参数传递是『引用传递』,明白了这一点就算是掌握了EventHook的基本原理。
其中Locust本身预定义并注册了一些处理函数,比如事件钩子report_to_master、worker_report都有对应的处理函数,实现分布式模式下数据上报时数据的构造和计算,比如事件钩子init,初始化master的WebUI。
三、事件钩子的作用
那么,事件钩子究竟有什么作用?
在我看来有以下作用:
- 代码解耦,比如解耦Runner和Stats模块。
- 提供扩展性,通过预置的钩子和触发点,为使用者提供了可扩展的特性。
举扩展性的例子,使用者可以很轻松地:
- 往worker上报的stats消息添加自定义数据
- 在Locust实例启动时在WebUI中添加自定义接口
- 在每次请求成功或失败之后做一些额外的事情
四、如何使用钩子
在Locust 1.x版本之前,使用以下方法定义和注册钩子:
def on_report_to_master(client_id, data):
data["stats"] = global_stats.serialize_stats()
data["stats_total"] = global_stats.total.get_stripped_report()
data["errors"] = global_stats.serialize_errors()
global_stats.errors = {}
def on_slave_report(client_id, data):
for stats_data in data["stats"]:
entry = StatsEntry.unserialize(stats_data)
request_key = (entry.name, entry.method)
if not request_key in global_stats.entries:
global_stats.entries[request_key] = StatsEntry(global_stats, entry.name, entry.method)
global_stats.entries[request_key].extend(entry)
...
events.report_to_master += on_report_to_master
events.slave_report += on_slave_report
在1.x及之后的版本有两种使用方式:
# 方式一与之前类似
def on_report_to_master(client_id, data):
data["stats"] = stats.serialize_stats()
data["stats_total"] = stats.total.get_stripped_report()
data["errors"] = stats.serialize_errors()
stats.errors = {}
def on_worker_report(client_id, data):
for stats_data in data["stats"]:
entry = StatsEntry.unserialize(stats_data)
request_key = (entry.name, entry.method)
if not request_key in stats.entries:
stats.entries[request_key] = StatsEntry(stats, entry.name, entry.method, use_response_times_cache=True)
stats.entries[request_key].extend(entry)
for error_key, error in data["errors"].items():
if error_key not in stats.errors:
stats.errors[error_key] = StatsError.from_dict(error)
else:
stats.errors[error_key].occurrences += error["occurrences"]
stats.total.extend(StatsEntry.unserialize(data["stats_total"]))
events.report_to_master.add_listener(on_report_to_master)
events.worker_report.add_listener(on_worker_report)
# 方式二,使用装饰器
@events.report_to_master.add_listener
def on_report_to_master(client_id, data):
"""
This event is triggered on the worker instances every time a stats report is
to be sent to the locust master. It will allow us to add our extra content-length
data to the dict that is being sent, and then we clear the local stats in the worker.
"""
data["content-length"] = stats["content-length"]
stats["content-length"] = 0
@events.worker_report.add_listener
def on_worker_report(client_id, data):
"""
This event is triggered on the master instance when a new stats report arrives
from a worker. Here we just add the content-length to the master's aggregated
stats dict.
"""
stats["content-length"] += data["content-length"]
第二种方式更加简洁,不容易忘记注册处理函数。have fun!