Locust的性能缺陷
一、GIL
熟悉Python的人应该都知道,基于cpython编译器的python天生就受限于它的全局解释锁GIL(global interpreter lock),尽管可以使用jython、pypy摆脱GIL但是很多经典的库在它们上面还没有经过严格的测试。好在Locust使用基于gevent的协程来实现并发,实际上,使用了 libev 或者 libuv 作为eventloop的gevent可以极大地提高Python的并发能力,拥有不比JAVA多线程并发模型差的能力。然而,还是由于GIL,gevent也只是释放了单核CPU的能力,导致Locust的并发能力必须通过起与CPU核数相同的slave才能发挥出来。
二、性能不佳的requests库
Locust默认使用requests作为http请求库,了解requests库的人,无不惊讶于它设计得如此精妙好用的API。然而,在性能上却与它的易用性相差甚远,如果需要提高施压能力,可以使用fasthttp,预估能提高5倍左右的性能,但是正如Locust作者所说的,fasthttp目前并不能完全替代requests。
三、rt评估不准
相信有些人吐槽过,在并发比较大的情况下,Locust的响应时间rt波动比较大,甚至变得不可信。rt是通过slave去统计的,因此并发大导致slave不稳定也是Locust被人诟病的问题之一,下面我们看一张压测对比图:
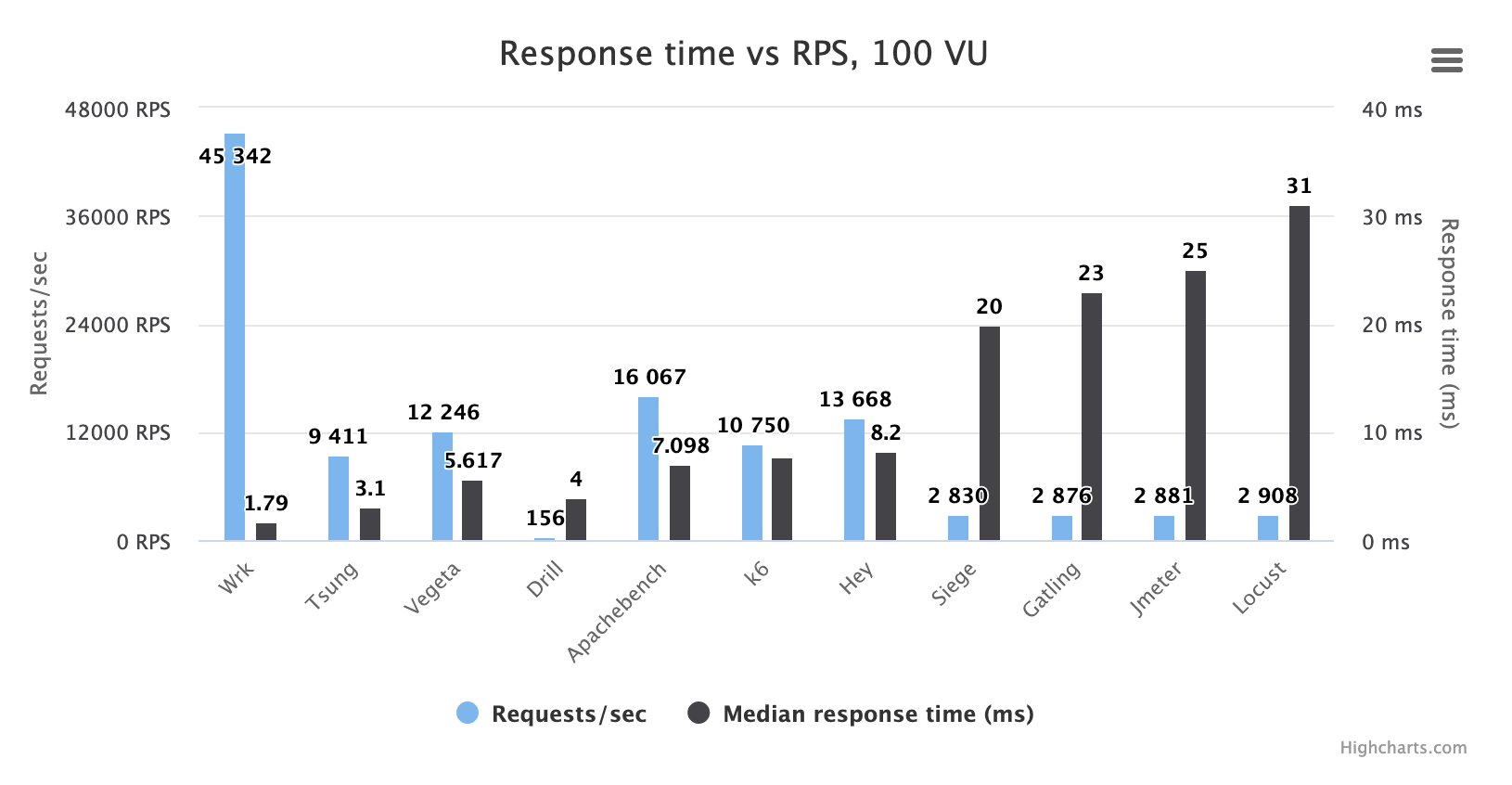
简单说明上图中显示的是在100并发下,各个压测工具对相同系统压测(未到瓶颈),响应时间的中位数。可以看到接口正常rt应该在2ms以内,而Locust统计到的却是30ms。(可以看到jmeter也好不到哪里去,真是难兄难弟~)
以上便是我认为Locust目前所面临的性能问题,只有解决了这三个问题,才能让Locust成为真正能够投入『生产使用』的工具。随着整体测试人员能力的提升,与Jmeter的GUI界面点点点的方式相比,Locust的可编程性、灵活性和可玩性会更强一些,颇有些hack for fun的感觉。
如何提高Locust的施压性能
一、增加slave?
原理上,支持分布式压测的系统都可以通过不断地增加施压机来提高并发能力,但是这会增加机器成本和维护成本,Locust不仅支持单机、也支持分布式压测,但是,不断增加slave显然不是一个很好的方案。
二、多线程or多进程?
Python多线程受GIL的影响较大,只有在IO密集型的场景下才能体现并发的优势,如果线程与并发用户是一一对应的关系,那么就又回到GIL的问题了,无法获得令人满意的并发性能,如果是线程与并发用户是一对多,那不如使用协程。而多进程,采用单slave多进程的方式似乎可以摆脱GIL的影响,单机可以不用起那么多slave,但是这与单机多slave相比性能并没有得到本质上的提升,此外单slave多进程的方式无疑会造成多进程间的IPC消耗,更不用说实现上的复杂程度了。
三、换一种语言?
有没有可能换一种语言?重新实现一套施压端slave端的逻辑?这种语言需要天生拥有强大的并发能力,支持与master沟通的语言Zeromq。
还真的有这样的语言: Golang
Golang下的goroutine
- 可以理解是用户态线程,goroutine的切换没有内核开销
- 内存占用小,线程栈空间通常是 2M,goroutine 栈空间最小 2K
- G-M-P调度模型
那么有没有一个开源项目是用go实现了Locust的slave端呢?
答案是有的,它就是: boomer
目前boomer除了比较完整实现了Locust的slave端逻辑,还内置支持指定TPS,理论上支持任意协议的压测。
然而,boomer对Locust那套Event机制支持的不足,也无法把自定义数据上报给master,但不妨碍它成为一个优秀的压力生成器。