统计对象
从Runner通信机制那篇文章中我们知道有一个非常重要的消息类型——stats,这个是slave给master发送的消息,默认每3秒钟上报一次。stats消息的结构如下所示:
{
"stats": [],
"stats_total": {},
"errors": {},
"user_count": 10
}
实际上,slave也是持有着类似如上json格式的三个对象:
- RequestStats
- StatsEntry
- StatsError
其中每一个locust进程会维护一个全局RequestStats单例global_stats,这个实例包含一个StatsEntry实例total(对应json的stats_total),以及两个字典entries(对应json的stats)和errors(对应json的errors),其中entries字典key为(name,method),对应值为一个StatsEntry实例,另一个errors字典的key为(name,method,error),对应值为一个StatsError实例。可见,global_stats包含了单个slave汇总的信息,以及各个请求url或name的统计信息。在分布式的场景下,每个slave都会维护一个global_stats, 在一个上报周期达到后将信息发送到master,发送完成后就会重置所有数据,进入下一个周期的统计。
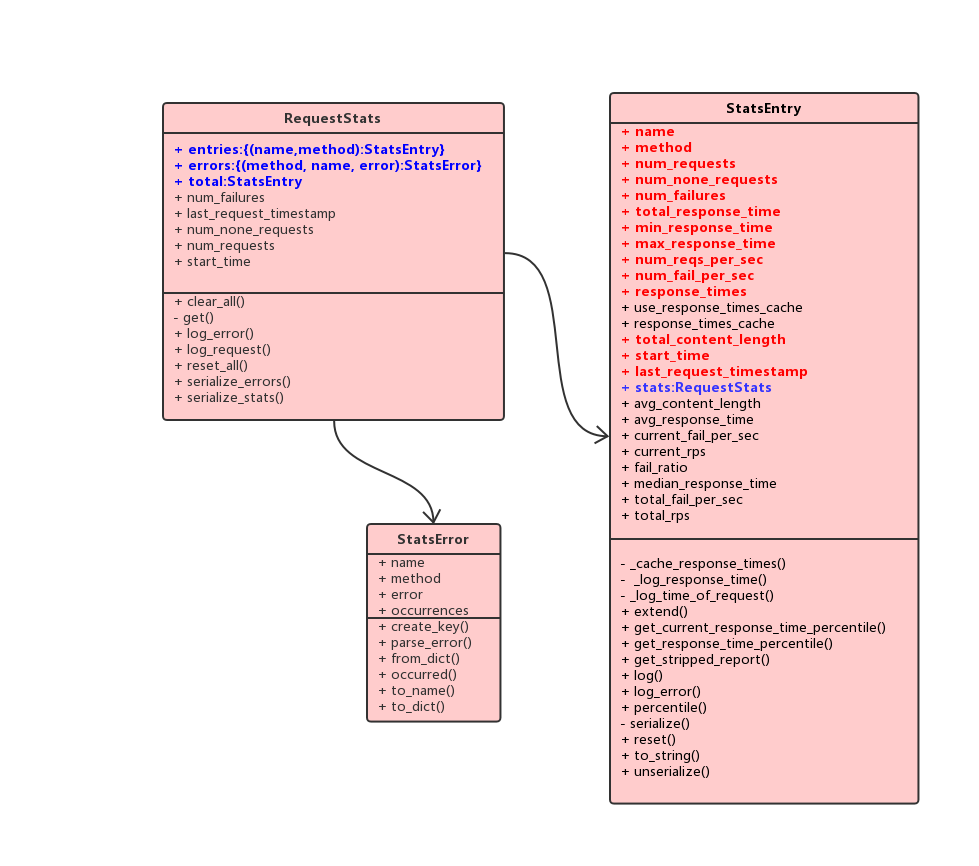
上图中红色的字段是slave真正上报给master的数据。
统计过程
那么slave是如何统计消息,又究竟需要上报什么内容给master?master又是如何汇总的呢?下面我们来看看整个统计过程:
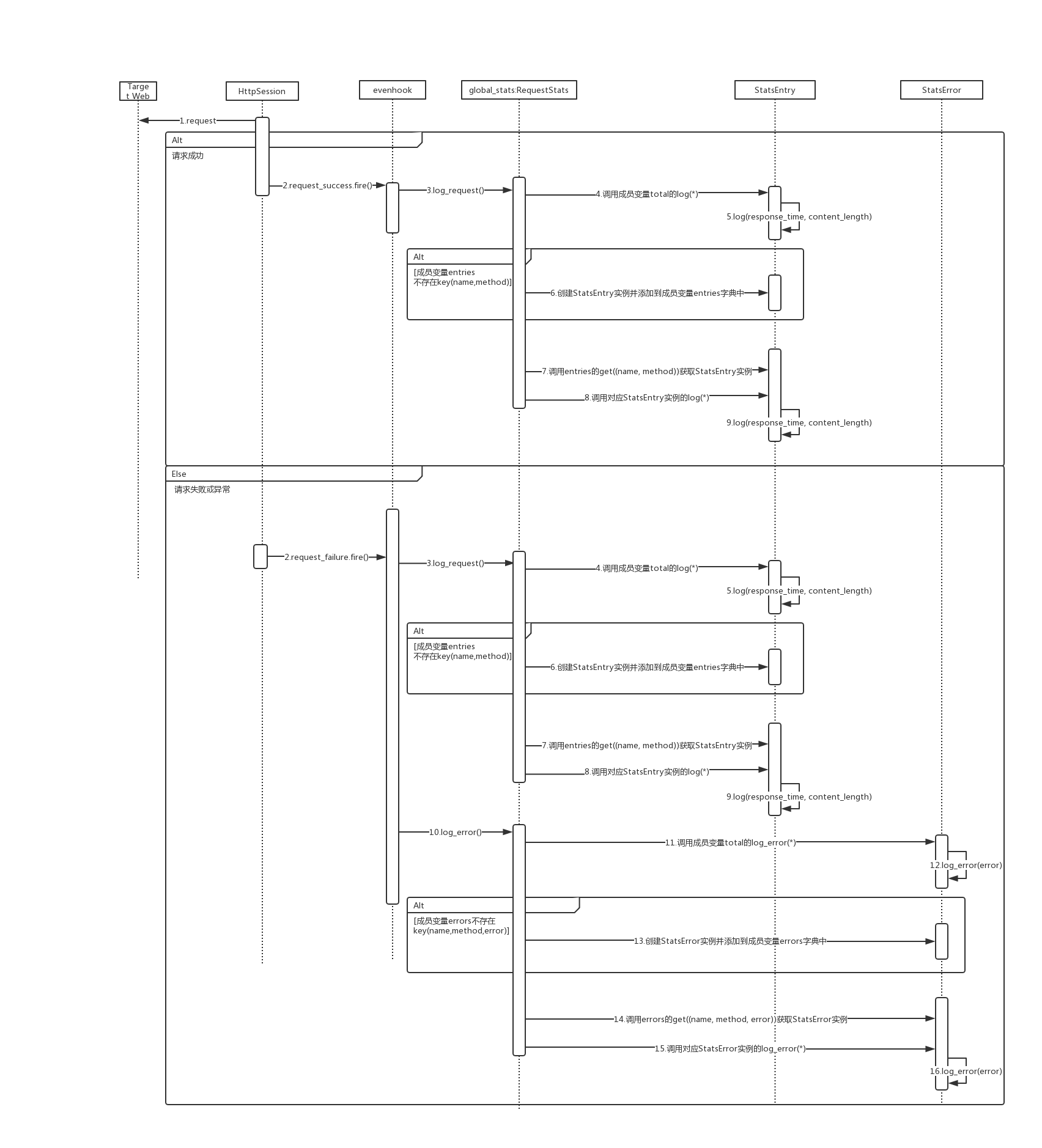
在每一次请求后,无论是成功还是失败,都会触发对应的request_success或者request_failure事件,stats.py文件中的数据统计模块订阅了对应的事件,会调用global_stats对数据进行统计。
在slave的一个上报周期达到后,触发on_report_to_master事件,此时global_stats就会依次调用以下方法对数据进行序列化:
- serialize_stats
- total.get_stripped_report
- serialize_errors
其实也就是对上面提到的total和两个字典中的内容进行序列化,其实就是转为json字符串。
def on_report_to_master(client_id, data):
data["stats"] = global_stats.serialize_stats()
data["stats_total"] = global_stats.total.get_stripped_report()
data["errors"] = global_stats.serialize_errors()
global_stats.errors = {}
下图是断点过程看到的stats消息内容(在msgpack序列化之前):

每秒请求数和响应时间及其对应请求个数
StatsEntry有两个比较重要的对象,分别是num_reqs_per_sec和response_times,它们都是字典类型,其中num_reqs_per_sec的key是秒时间戳,显示当前秒完成了多少个请求,统计的时间是完成请求的时刻,比如如果一个请求从第0秒开始,第3秒完成,那么这个请求统计在第3秒的时间戳上,这个对象可以很方便的计算出rps。response_times的key是响应时间,单位是豪秒,为了防止key过多,做了取整,比如147 取 150, 3432 取 3400 和 58760 取 59000,这个是为了方便获得类似90%请求的完成时间(小于等于该时间),99%请求的完成时间,下面具体的源码:
def _log_time_of_request(self, current_time):
t = int(current_time)
self.num_reqs_per_sec[t] = self.num_reqs_per_sec.setdefault(t, 0) + 1
self.last_request_timestamp = current_time
def _log_response_time(self, response_time):
if response_time is None:
self.num_none_requests += 1
return
self.total_response_time += response_time
if self.min_response_time is None:
self.min_response_time = response_time
self.min_response_time = min(self.min_response_time, response_time)
self.max_response_time = max(self.max_response_time, response_time)
# to avoid to much data that has to be transfered to the master node when
# running in distributed mode, we save the response time rounded in a dict
# so that 147 becomes 150, 3432 becomes 3400 and 58760 becomes 59000
if response_time < 100:
rounded_response_time = response_time
elif response_time < 1000:
rounded_response_time = int(round(response_time, -1))
elif response_time < 10000:
rounded_response_time = int(round(response_time, -2))
else:
rounded_response_time = int(round(response_time, -3))
# increase request count for the rounded key in response time dict
self.response_times.setdefault(rounded_response_time, 0)
self.response_times[rounded_response_time] += 1
master汇总信息
slave的每一个stats消息到达master后,都会触发master的slave_report事件,master也拥有自己的global_stats,因此只需要将对应的信息进行累加(可以理解是所有slave对应内容的汇总)。具体在StatsEntry的extend方法:
def extend(self, other):
"""
Extend the data from the current StatsEntry with the stats from another
StatsEntry instance.
"""
if self.last_request_timestamp is not None and other.last_request_timestamp is not None:
self.last_request_timestamp = max(self.last_request_timestamp, other.last_request_timestamp)
elif other.last_request_timestamp is not None:
self.last_request_timestamp = other.last_request_timestamp
self.start_time = min(self.start_time, other.start_time)
self.num_requests = self.num_requests + other.num_requests
self.num_none_requests = self.num_none_requests + other.num_none_requests
self.num_failures = self.num_failures + other.num_failures
self.total_response_time = self.total_response_time + other.total_response_time
self.max_response_time = max(self.max_response_time, other.max_response_time)
if self.min_response_time is not None and other.min_response_time is not None:
self.min_response_time = min(self.min_response_time, other.min_response_time)
elif other.min_response_time is not None:
# this means self.min_response_time is None, so we can safely replace it
self.min_response_time = other.min_response_time
self.total_content_length = self.total_content_length + other.total_content_length
for key in other.response_times:
self.response_times[key] = self.response_times.get(key, 0) + other.response_times[key]
for key in other.num_reqs_per_sec:
self.num_reqs_per_sec[key] = self.num_reqs_per_sec.get(key, 0) + other.num_reqs_per_sec[key]
for key in other.num_fail_per_sec:
self.num_fail_per_sec[key] = self.num_fail_per_sec.get(key, 0) + other.num_fail_per_sec[key]
核心指标
Locust核心的指标其实就4个:
- 并发数
- RPS
- 响应时间
- 异常率
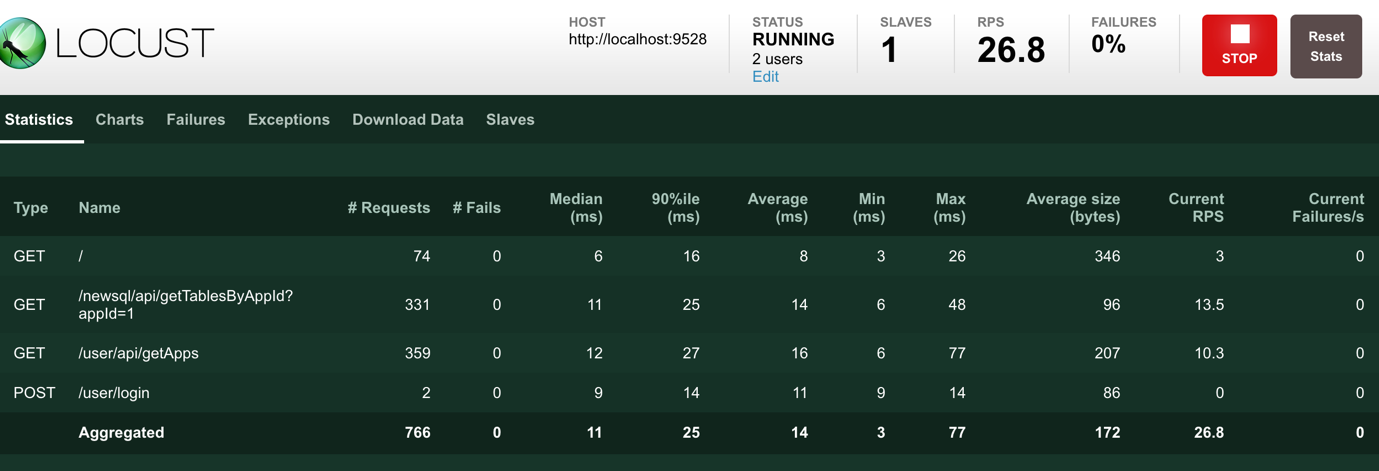
我们还是回到文章开头的那个json:
{
"stats": [],
"stats_total": {},
"errors": {},
"user_count": 10
}
结合上方Locust的压测过程截图,我们可以看到,各个接口的指标其实就是stats对象里的各个字段,而最下方汇总的Aggregated这一行则对应stats_total的各个字段,尽管这个json只是slave单个stats消息的内容,却也是最终要显示的内容,只是master对各个消息做了汇总而已。汇总的方式也相当简单,请见上方的StatsEntry的extend方法。
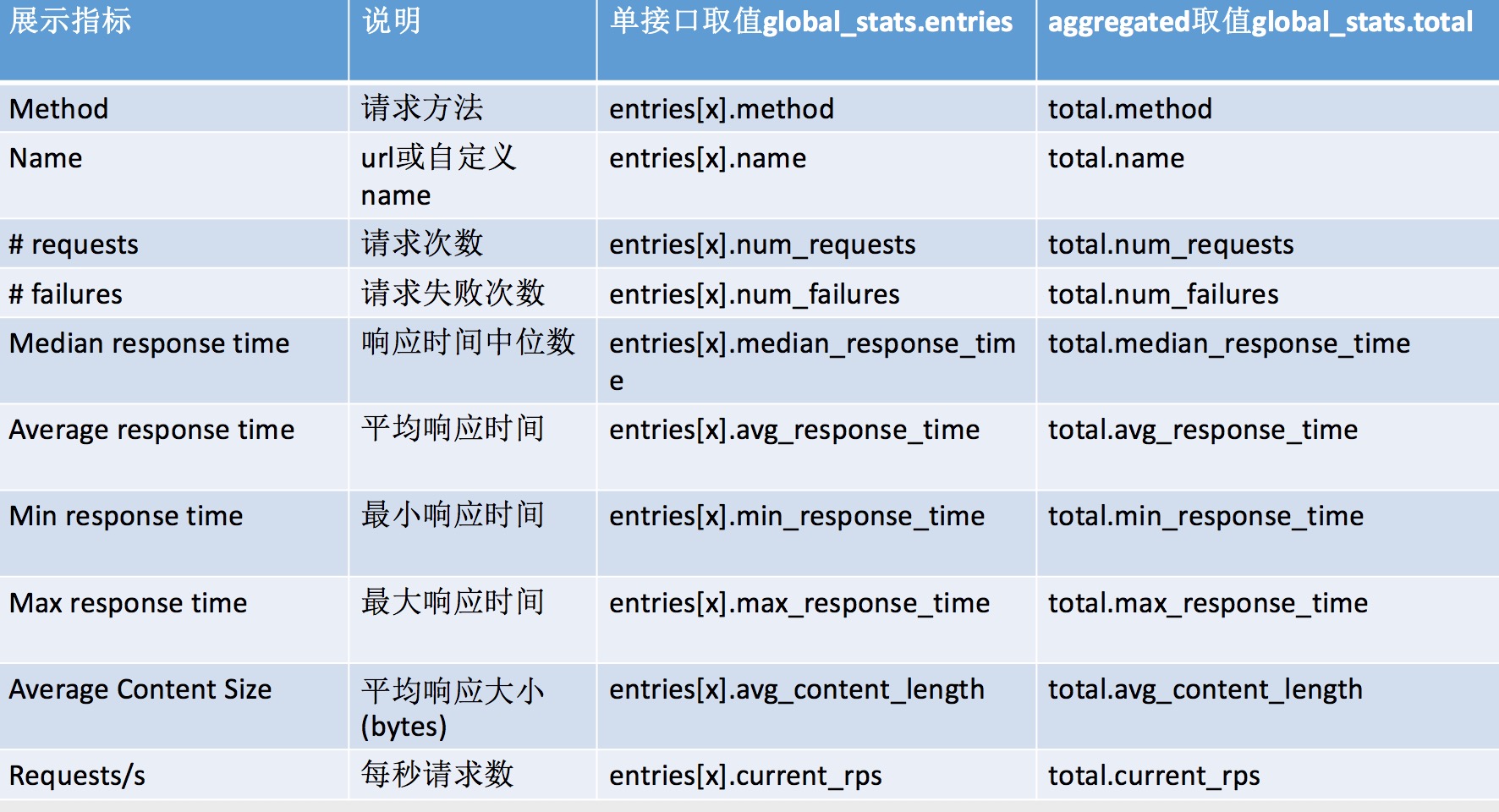
因为master和web模块是一起部署的,因此web可以直接使用master的global_stats对象并展示其内容,可以做到动态显示。